

تم شحن الذكاء الاصطناعي السائل للتو LFM2.5-8B-A1B. وهو عبارة عن نموذج خليط من الخبراء (MoE) الموجود على الجهاز والذي تم تصميمه لاستدعاء الأدوات. يحتوي النموذج على 8.3 مليار معلمة إجمالية ولكنه ينشط 1.5 مليار فقط لكل رمز مميز. هذا التناثر هو ما يتيح تشغيله على الأجهزة الاستهلاكية.
يأتي الإصدار بعد LFM2-8B-A1B، الذي نشره فريق Liquid AI سابقًا. LFM2.5 هي عائلة جديدة من النماذج الهجينة للنشر على الجهاز. يضيف هذا الإصدار نافذة سياق بحجم 128 كيلو بايت، واستدلالًا، وتدريبًا موسعًا.
ما هو LFM2.5-8B-A1B
يستخدم النموذج تصميم MoE المتناثر. يقوم بتنشيط 1.5B من إجمالي 8.3B من المعلمات لكل تمريرة أمامية. وهذا يبقي كل رمز مميز تم إنشاؤه رخيصًا لحسابه.
تتكون البنية من 24 طبقة. ثمانية عشر عبارة عن كتل تلافيفية ذات بوابات مزدوجة LIV؛ ستة هي طبقات GQA. فهو يجمع بين MoE وGQA وكتل تلافيفية قصيرة مسورة. طول السياق هو 131.072 رمزًا. يغطي النموذج تسع لغات، بما في ذلك العربية والصينية واليابانية.
يوصي فريق Liquid AI بدرجة حرارة 0.2، وأعلى درجة حرارة 80، وعقوبة التكرار 1.05.
على عكس سابقه، يعد LFM2.5-8B-A1B نموذجًا للاستدلال فقط. وتنتج سلسلة واضحة من الأفكار قبل إجابتها النهائية. اختار فريق Liquid AI هذا لأن نماذج MoE تعمل في إعدادات مرتبطة بالحوسبة. إن عدد المعلمات النشطة الأصغر يجعل كل رمز منطقي غير مكلف.
ما الذي تغير منذ LFM2-8B-A1B
قام Liquid بتوسيع نافذة السياق من 32768 إلى 128000 رمزًا. تم زيادة التدريب المسبق من 12T إلى 38T من الرموز. تضاعفت المفردات من 65.536 إلى 128.000 رمزًا.
تعمل المفردات الأكبر حجمًا على ترميز النصوص غير اللاتينية بشكل أكثر كفاءة. أبلغ فريق Liquid AI عن أقوى مكاسب الضغط باللغات الهندية والتايلاندية والفيتنامية والإندونيسية والعربية. تظل بقية البنية كما هي LFM2-8B-A1B.
كيف قام الذكاء الاصطناعي السائل بتدريبه
قام فريق Liquid AI بتوسيع الرمز المميز في مكانه بدلاً من إعادة التدريب من الصفر. لقد استمر في التدريب على دمج BPE من عمليات الدمج الأصلية في مجموعة متعددة اللغات. تتم تهيئة صفوف التضمين الجديدة كوسيلة لتحليل الرموز الفرعية الخاصة بها. ومن ثم يستعيد التكيف القصير على مرحلتين الجودة.
جاء امتداد السياق على مرحلتين. وصلت مرحلة التدريب المتوسط لرمز 2T إلى 32 ألفًا، مع التركيز على التفكير والرياضيات واستخدام الأدوات. وصل رفع قاعدة RoPE θ، بالإضافة إلى مرحلة الرمز المميز 400B، إلى 128 ألفًا.
تستهدف مرحلتان للتعلم المعزز أوضاع الفشل المعروفة. تعمل مرحلة تحسين التفضيل على تقليل “حلقات الموت” في مسارات التفكير الطويلة. إنه يعيد توزيع كتلة الاحتمالية نحو البدائل المعقولة. تعمل مكافأة تشكيل RL المنفصلة على تثبيط كلمات إعادة التشغيل المحفزة للحلقة مثل “انتظر…”. تستخدم مرحلة RL أخرى مكافأة تعتمد على متوسط @k لتقليل الهلوسة. والهدف هو الامتناع عن الأسئلة التي تتجاوز المعرفة الموثوقة.
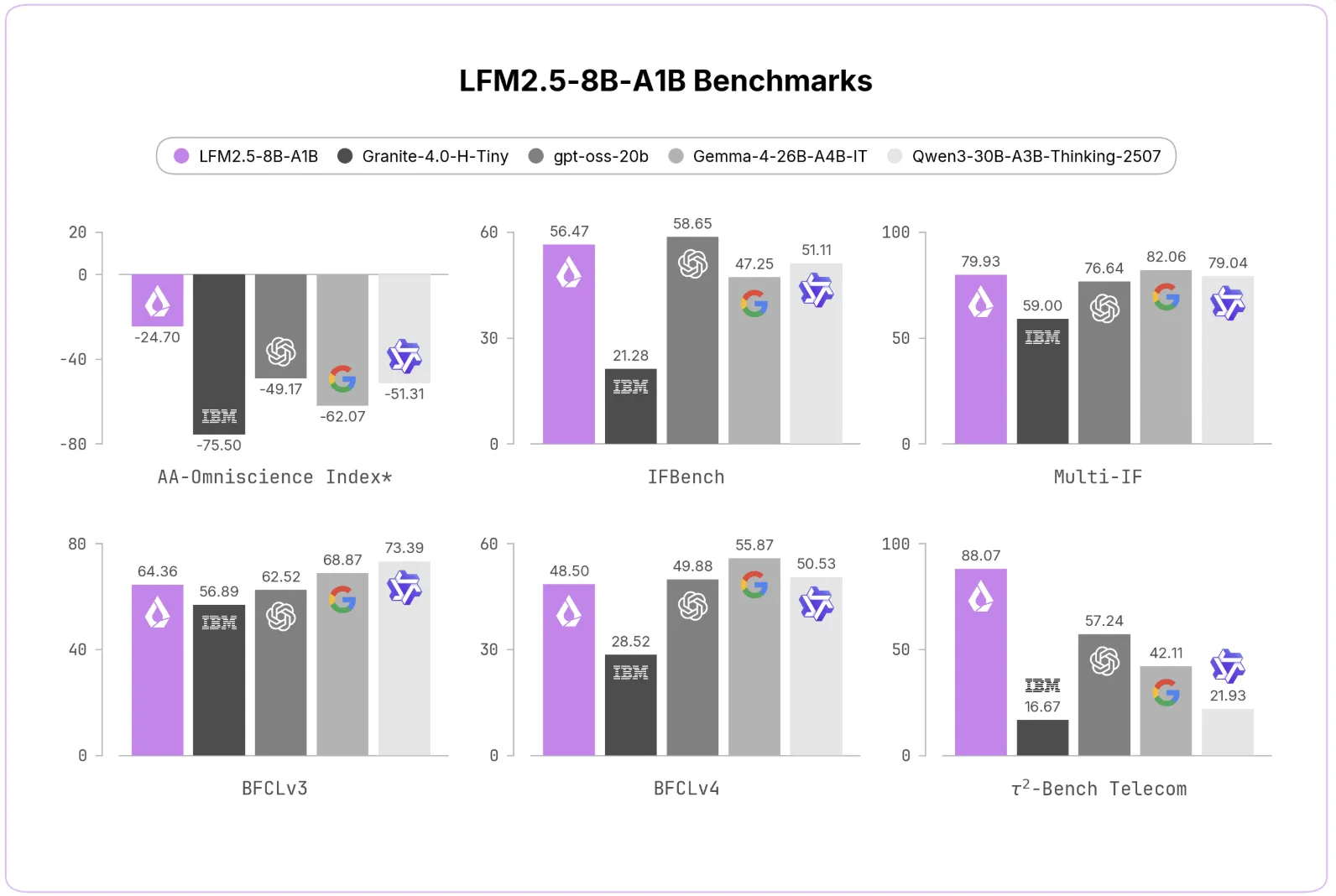
القضية المرجعية
تم تحسين LFM2.5-8B-A1B مقارنة بسابقه في جميع المجالات. قفز معدل عدم الهلوسة AA-Omniscience من 7.46 إلى 63.47. وارتفع مؤشر IFEval من 79.44 إلى 91.84. ارتفع MATH500 من 74.80 إلى 88.76. ارتفع سهم Tau² Telecom من 13.60 إلى 88.07.
قام فريق Liquid AI بمقارنة النموذج بالبدائل الكثيفة وMoE. وفقًا للتعليمات التالية، فإنه يطابق Gemma-4-26B-A4B-IT على IFEval. وهو يفعل ذلك بجزء صغير من عدد المعلمات النشطة. في Tau² Telecom، حصلت على 88.07، متقدمة على الموديلات الأكبر بكثير.
تؤدي المكافأة المتوسطة إلى معدل هلوسة أقل بكثير. تظل الدقة معقولة بالنسبة لحجم النموذج. فيما يتعلق بمعايير الوكيل، تظل قادرة على المنافسة مع النماذج الأكبر.
| المعيار | LFM2-8B-A1B | LFM2.5-8B-A1B | Δ |
|---|---|---|---|
| AA-معدل عدم الهلوسة في كلي العلم | 7.46 | 63.47 | +56.01 |
| IFEval | 79.44 | 91.84 | +12.40 |
| الرياضيات500 | 74.80 | 88.76 | +13.96 |
| تاو² للاتصالات | 13.60 | 88.07 | +74.47 |
يأتي النموذج مع دعم اليوم الأول عبر النظام البيئي للاستدلال. تتضمن الأطر llama.cpp وMLX وvLLM وSGLang. يتم أيضًا دعم منصة ONNX وLiquid’s LEAP edge.
على وحدة المعالجة المركزية، يقوم بفك تشفير 253 رمزًا/ثانية على M5 Max. يصل إلى 146 رمزًا / ثانية على Ryzen AI Max + 395. ويظل أقل من 6 جيجابايت من الذاكرة طوال الوقت. على الهاتف، يحمل حوالي 30 رمزًا/ثانية.
على جهاز NVIDIA H100 SXM5 واحد، يصل إنتاجية الإخراج إلى 18.5 ألف رمز في الثانية. وهذا يزيد عن 1.6 مليار رمز يوميًا بتزامن عالٍ.
لاستخدام الأداة، يكتب LFM2.5 استدعاءات دالة Pythonic افتراضيًا. تظهر بين <|tool_call_start|> و <|tool_call_end|> الرموز الخاصة. يمكنك تجاوز هذا إلى JSON في موجه النظام.
نقاط القوة وماذا تشاهد
نقاط القوة:
- ينشط 1.5 مليار معلمة فقط، مما يجعل الاستدلال رخيصًا على الأجهزة المتطورة
- تعليمات تنافسية ودرجات وكيلة لفئة حجمها
- نافذة سياق 128 كيلو بايت وتغطية بتسع لغات
- وزن مفتوح بموجب ترخيص LFM1.0، مع نقاط تفتيش أساسية وما بعد التدريب
ما يجب مشاهدته:
- قدرة معرفية محدودة من عدد المعلمات النشطة الصغيرة
- لا يصلح للبرمجة الثقيلة أو ضمان الجودة كثيفة المعرفة دون استرجاعها
- يضيف الإخراج المنطقي فقط رموزًا مميزة لسلسلة الأفكار إلى كل منعطف
- نص فقط؛ هذا المتغير لا يحتوي على رؤية أو إدخال صوتي
الشرح المرئي لـ Marktechpost
الوجبات السريعة الرئيسية
- يحتوي LFM2.5-8B-A1B الخاص بـ Liquid AI على 8.3 مليار معلمة إجمالية ولكنه ينشط 1.5 مليار فقط لكل رمز مميز.
- إنه منطقي فقط، مع نافذة سياق بحجم 128 كيلو بايت وتغطية بتسع لغات.
- قفز معدل عدم الهلوسة من 7.46 إلى 63.47 على LFM2-8B-A1B؛ وصلت IFEval إلى 91.84.
- يقوم بفك تشفير 253 tok/s على M5 Max أقل من 6 جيجابايت، و~30 tok/s على الهاتف.
- يمتد دعم اليوم الأول إلى llama.cpp وMLX وvLLM وSGLang، مع قاعدة مفتوحة وأوزان ما بعد التدريب.
تحقق من الأوزان النموذجية و التفاصيل الفنية. أيضا، لا تتردد في متابعتنا على تغريد ولا تنسى الانضمام إلينا 150 ألف+ مل من SubReddit والاشتراك في النشرة الإخبارية لدينا. انتظر! هل أنت على برقية؟ الآن يمكنك الانضمام إلينا على التليجرام أيضًا.
هل تحتاج إلى الشراكة معنا للترويج لصفحة GitHub Repo أو صفحة الوجه المعانقة أو إصدار المنتج أو الندوة عبر الويب وما إلى ذلك؟ تواصل معنا
اكتشاف المزيد من كحيل للتقنية | أخبار التقنية والذكاء الاصطناعي وشروحات الويب
اشترك للحصول على أحدث التدوينات المرسلة إلى بريدك الإلكتروني.